Every conversational analytics vendor is selling you the same requirements for your data agent to be successful: Better semantic layers. Cleaner column naming. Optimize system prompting.
They're solving the technical challenge while ignoring the user experience gap (a gap that I've heard now for 2 years working on this problem).
What vendors won't tell you is that the real barrier to adoption isn't SQL accuracy, it's verification. The inspiration for today's article came from DeepSeek's October 2025 research suggesting visual representations may be 10x more token-efficient than text for LLM comprehension. If images are more efficient for the model AND more trustworthy for users, should vision be a part of your data foundation for conversational analytics.
What Users Actually Need
I chose NCAA basketball because 1. It's my favorite sport and 2. StatMuse doesn't cover it. If conversational analytics really works, AI should be able to handle sports queries just as well as a human-curated database. College basketball became the proving ground: could vision-powered conversational analytics match what specialized tools provide for professional sports?
The implementation was straightforward: I built a Streamlit dashboard displaying ESPN-style box scores for games, then captured screenshots of each box score. These screenshots became the visual context layer, static images of the data users were already familiar with reading. Then I let the agents loose on answering questions about those games.
When users asked "Who scored the most points for Duke?", two agents ran in parallel:
- Visual Context Agent analyzing the box score screenshots using Claude Vision
- SQL Generation Agent creating queries from scratch against the game database
Both returned correct answers. But the visual agent won every time on user confidence.
Why? It returned the answer PLUS the box score image. "Isiah Evans with 21 points" alongside the actual Duke box score showing the stat line. Users could verify it instantly with the same ESPN-style layout they'd been reading for years, just now served up by an AI that could parse it.
This wasn't about better accuracy with both agents getting to the right answer most of the time. It was about giving users a way to confirm the answer matched what they expected to see. And the DeepSeek efficiency hypothesis held: the visual agent processed the entire box score layout (teams, scores, 10+ players with 15 stats each) in a single vision call, while the SQL agent needed schema parsing, query generation, and result formatting.
Why This Matters Beyond Basketball
Towards AI's analysis documents why Text2SQL remains unreliable with ambiguous questions, schema complexity, semantic gaps. But even if you reached 100% SQL accuracy, business users still can't verify answers. They can't read SQL or debug joins. They can't spot when "revenue" excludes returns or uses a different date range.
When your VP asks for Q4 Northeast revenues and gets "$4.2M" but her dashboard shows "$4.1M", she doesn't know if the tool is wrong or measuring differently. With SQL alone, she's stuck. With a dashboard image, she can spot the discrepancy and debug it herself.
Dashboard images solve the verification gap by giving users confirmation in a format they already trust. And if DeepSeek's research holds, they do it more efficiently than text-based approaches.
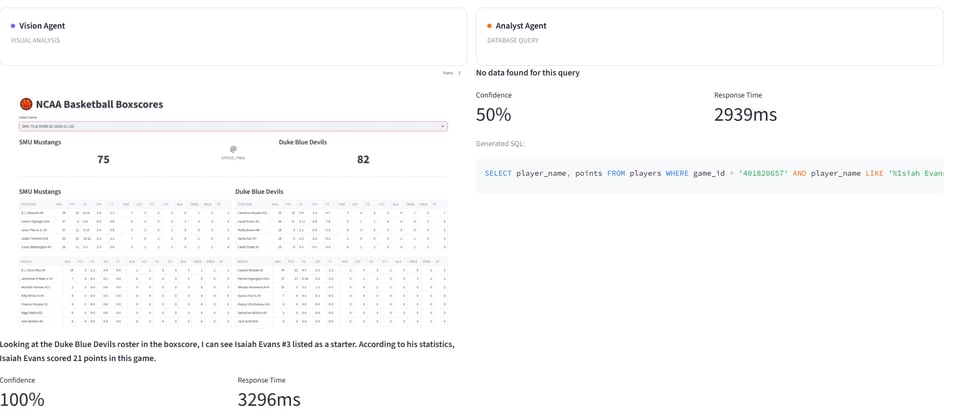
Results: Now try debugging to your manager why the SQL doesn't work, but with Vision you have the right answer and the validation.
Prototype Meeting Enterprise Walls
As exciting of a result that this gave us, testing with 10 games does reveal why dashboard images aren't a complete solution:
Composition doesn't work. Questions like "Compare Duke's shooting across their last 3 games" require fetching 3 separate screenshots. The visual agent can analyze each one, but can't generate a unified view the way SQL joins and aggregates across games. Users end up mentally merging multiple images - exactly what conversational analytics promised to eliminate.
Filter variations explode. My prototype had one filter (game selector). Real dashboards have regions, time periods, product categories, customer segments - creating thousands of possible states. You can't pre-generate them all. Generating on-demand means every query waits for image rendering. At enterprise scale with hundreds of dashboards refreshing daily, you're not just dealing with terabytes of images - you're building image storage infrastructure most data teams don't have.
Not every dashboard is table based. Yes, a lot of dashboards end up being glorified spreadsheets, but not all of them do, which becomes an issue here. If you have line/bar charts in the dashboard without the numbers revealed, the insights will stay hidden. I did see vision could do a solid interpretation about picking up how things were trending, but it won't have the context for specific values.
Dashboards like this would be a nightmare for Vision without access to data
What This Reveals
The NCAA basketball test proved images are a data point that conversational analytics will need. We saw that we could build an asset that helps users get verified answers they trusted because they could see the validation by looking at an image not reading another language.
But the constraints are real: Text2SQL gives you composable, scalable queries users will struggle to verify. Dashboard images give you verifiable answers that don't compose and struggle to scale without investment in data infrastructure.
Could Vision Token Efficiency Be the Key?
If vision tokens are 10x more efficient than text, maybe the answer isn't storing screenshots but generating visual representations on the fly. Mass Mural's GenBI work explores this: create dashboard-style visualizations dynamically rather than storing static images. This solves storage. But composition remains unsolved.
The vendors that win conversational analytics won't do it with better SQL generators or prettier dashboards. They'll do it by solving verification at scale: How do you give users visual confirmation without storing infinite image variations? How do you maintain composability across multiple data sources while letting users validate each step?
Vision unlocks a verification layer conversational analytics has been missing. But until someone figures out how verification scales across complex, multi-source business questions, every conversational analytics tool will keep dying at the same point: the moment users ask "validate me please" and stare at an answer they can't confirm. The technical challenge is building better SQL. The market opportunity is building trust.
Streamlit App: https://textvsimagesyllabi.streamlit.app/
Github Repo: https://github.com/grosz99/textvsimage_syllabi
Thank you for reading. If you like the newsletter feel free to forward along and help drive new eyes to Syllabi!
